
Machine Translation Quality Evaluation & Post-Editing
About the project
The client needed to code responses to open-ended questions from a survey that collected data from Chinese speakers. The client tried to use machine translation, but the results were unsatisfactory and unreliable. The project faced several challenges, such as a large volume of data (~211K words), a tight deadline (one week), and a limited budget. The client sought an efficient and cost-effective solution that could ensure the quality and accuracy of the coding process. We identified an appropriate machine translation quality evaluation process.

Project Scope with cApStAn
Machine Translation Quality Evaluation
The project scope with cApStAn involved leveraging automated translation quality estimation to enhance the efficiency and accuracy of translating content.
- We selected and tested a Machine Translation (MT) engine that worked well for Chinese-to-English translation
- A Translation Quality Estimation (TQE) tool was also selected and tested to decide which metric to use for quality assurance
- A threshold was determined using the metric; translations above the threshold required no post-editing while those below it needed rapid post-editing (RPE)
- cApStAn post-edited a sample of responses above the threshold to validate the approach and ensure optimal translation quality
Methodology
- A human-in-the-loop methodology was employed to evaluate and enhance MT output
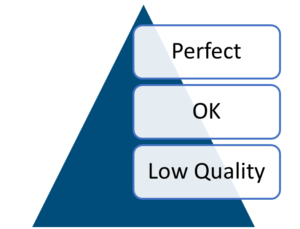
- A random 10% sample of the raw MT output was evaluated and post-edited by humans, categorizing translations into ‘Perfect’, ‘OK’, and ‘Low Quality’
- The same sample was also assessed by COMET, a metric that quantified translation quality between 0 and 1
- A COMET score threshold (between 0 and 1, with 1 = perfect) was established to differentiate between translation quality levels.
- In this case, a score below 0.8 correlated with ‘Low’ and ‘OK’ translations, so a threshold of 0.81 was deemed safe
Translation Process diagram
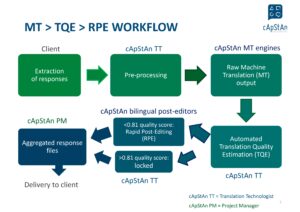
Human Rapid Post-editing (RPE)
- The post-editor worked on responses that scored ≤ 0.81
- Some serious issues were detected. Example of RPE below (segment with 0.7451 COMET score)
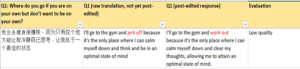
- As a final quality control step, we selected a sample of a few segments (that had a score of higher than 0.81. Over 95% of the segments passed the quality check.
Outcome Achieved
- Delivered the translations of 5708 responses (211K words) within 5 working days.
- We post-edited ~40% of the raw MT output, ensuring quality and accuracy in the translations
- cApStAn delivered the translations in the client’s survey response analysis format with post-edited segments highlighted, facilitating clarity and ease of understanding
- Provided comments to explain specific terms like “KTV” (Abbreviation for “karaoke in mainland China)
Applications & Caveats
THIS PROCESS IS SUITED FOR
- Automatically generated reports (e.g. of personality screening tests)
- Survey responses
- Interview transcriptions
THIS PROCESS IS NOT SUITED FOR
- High-stakes tests
- Publication grade content
- Executive summaries
SOME TESTING IS ALWAYS NEEDED
- MT output vary per language pair and per domain
- Thresholds to be determined for each project
Want to try this out on your materials?
Sign a mutual NDA and send your content along with the requirements. Request a quote at bizdev@capstan.be or contact us via the form below for more details.
See also, from our blog
“The translator of the future is a human-machine hybrid”
“Latest “IEA Insider” now out featuring article by cApStAn LQC co-founder Steve Dept”